CI for AI behavior
Stop the same AI failure from shipping twice
EvalGate captures real AI failures, promotes reviewed cases into reusable eval coverage, and blocks regressions before release.
Start local with no account. Add the platform when your AI reaches production scale.
Use the local gate first, then add traces, LLM judges, review workflows, cost controls, and governance as your team needs them.
How teams ship with EvalGate
One wedge: trace what breaks in the real world, promote it into eval coverage, then enforce it in CI.
Step 1
Start with one local gate
Install the SDK, snapshot your current behavior, and block regressions in CI before you adopt the full platform.
Step 2
Capture failures from real AI behavior
Trace production and staging behavior with structured context so reviewed evals reflect what users actually hit.
Step 3
Promote coverage into release gates
Turn failures into suites, run them on every change, and give reviewers evidence before a merge.
Built for the trace → eval → gate loop
Three reasons teams standardize on EvalGate for AI quality — not a broad platform catalog.
See It in Action
Every screen built for speed, clarity, and actionable insight
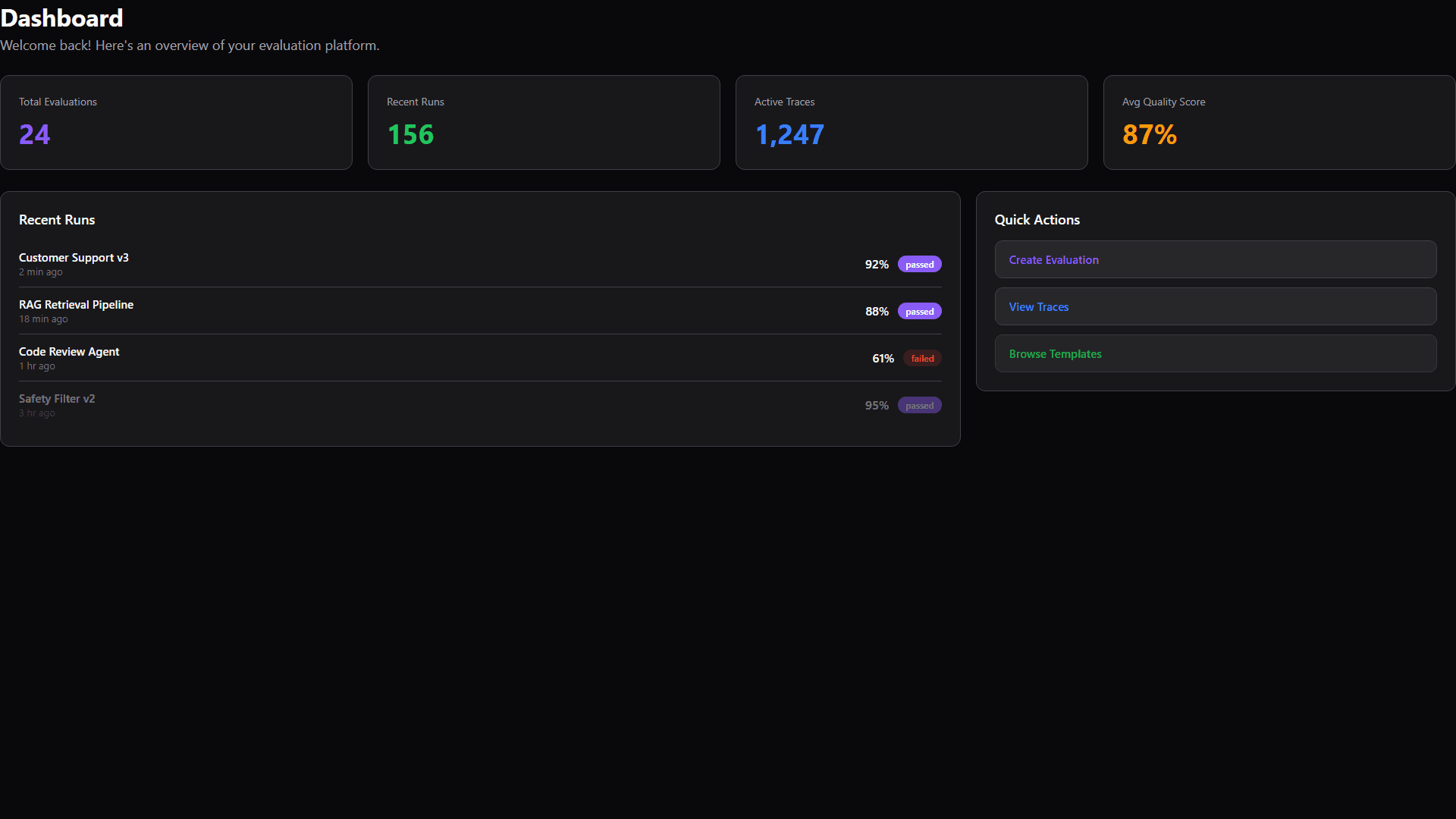
At-a-glance stats, recent runs, and quick actions
Try AI Evaluation in 30 Seconds
Choose a scenario below to run a real demo endpoint and see sample results instantly. Sign up to save results and use the API.