CI for AI behavior
Stop the same AI failure from shipping twice
EvalGate turns traces, labels, judges, and baselines into the release evidence reviewers need before an AI change ships.
Start local with no account. Model-backed workflows are BYOK—connect your own provider or gateway credential when you add judges and automation.
EvalGate does not bundle model inference credits. Your provider bills model usage; EvalGate adds evaluation, review, cost controls, and audit evidence.
5-minute gate proof
Two commands create a baseline, run the gate, and write a regression report reviewers can inspect.
evals/regression-report.json
Misses become coverage
Traced failures can be labeled, clustered, synthesized, reviewed, and promoted into reusable eval checkpoints.
trace -> label -> gate
Release evidence packet
Every gate can carry baseline diff, judge provenance, failure-mode deltas, and audit context into review.
PR summary + artifacts
How teams ship with EvalGate
One wedge: trace what breaks in the real world, promote it into eval coverage, then enforce it in CI.
Step 1
Start with one local gate
Install the SDK, snapshot your current behavior, and block regressions in CI before you adopt the full platform.
Step 2
Capture failures from real AI behavior
Trace production and staging behavior with structured context so reviewed evals reflect what users actually hit.
Step 3
Promote coverage into release gates
Turn failures into suites, run them on every change, and give reviewers a release packet before a merge.
Built for the trace -> eval -> gate loop
Three reasons teams standardize on EvalGate for AI quality - not a broad platform catalog.
Trust controls appear where the release decision happens
EvalGate ties every gate to artifacts reviewers, security leads, and platform owners can inspect.
Auditable baselines
Baseline, judge config, thresholds, and run artifacts stay tied to each release decision.
baseline diff + run artifact
Controlled judges
BYOK provider credentials, provider allowlists, PII policy, cost caps, and credibility thresholds run before judge calls are trusted.
BYOK key + policy check + judge credibility
Reviewed promotion
Production misses start as evidence, move through review, and only gate releases after promotion.
candidate -> approved -> promoted
Platform Depth
Built on a foundation of rigorous testing, comprehensive schema, and multi-language SDK support
Test Coverage
Comprehensive service-layer tests
Database Schema
Validated database tables
Reliability
Production-grade fault tolerance
SDK Support
TypeScript, Python, CLI
See It in Action
Every screen built for speed, clarity, and actionable insight
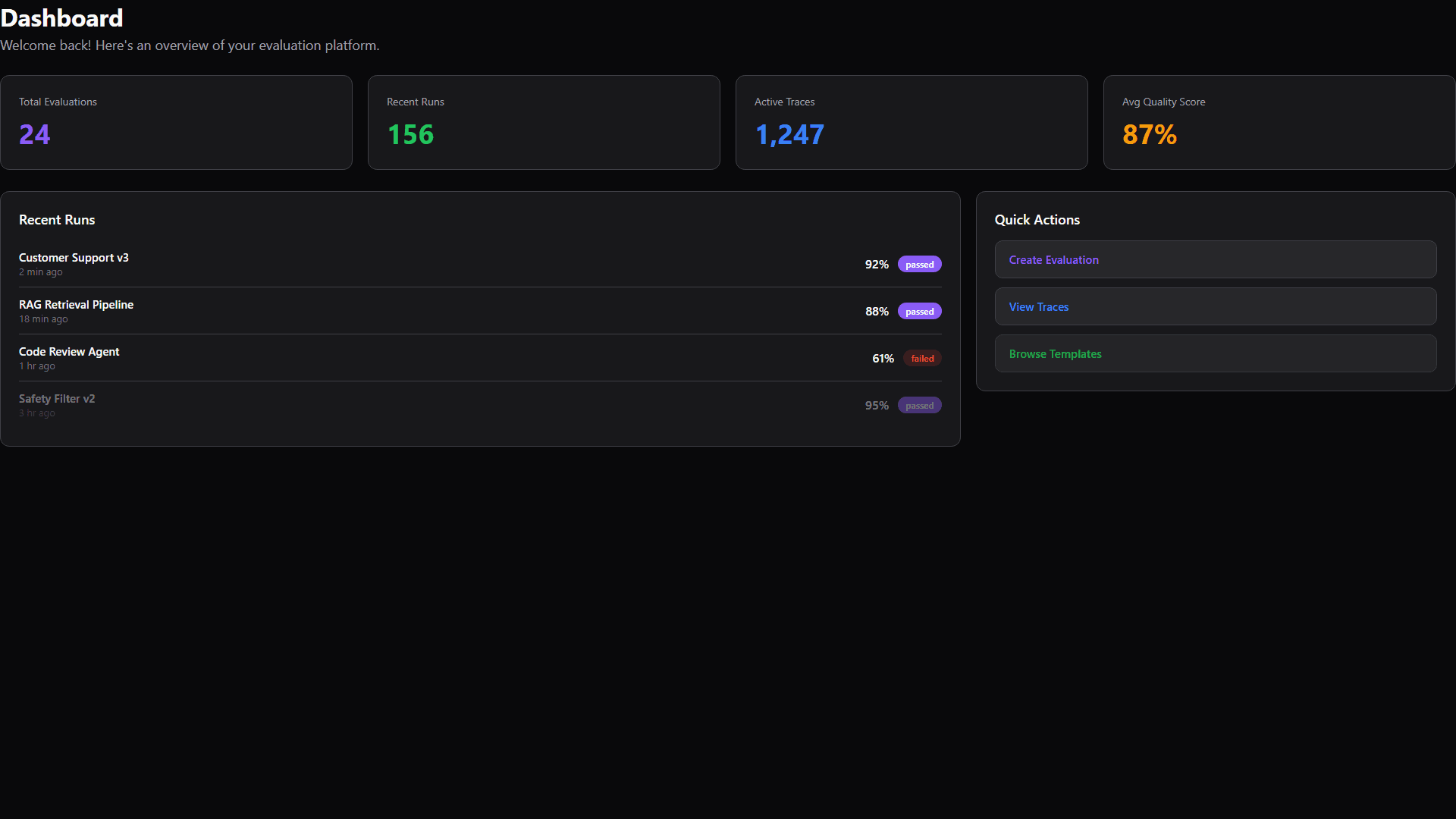
At-a-glance stats, recent runs, and quick actions
Try AI Evaluation in 30 Seconds
Choose a scenario below to run a real demo endpoint and see sample results instantly. Sign up to save results and use the API.